From Prompt Engineering to Harness Engineering
A practical reflection on why reliable AI agents depend less on clever prompts and more on the harness around them - ingestion pipelines, intentional knowledge representations, tool design, orchestration, role policy, and verifiable outputs.
For a while, I thought the hardest part of building useful AI agents would be prompt design. The deeper I got into production-style workflows, the more that assumption started to break down.
The prompt still matters. It sets tone, constraints, and task boundaries. But the biggest improvements did not come from finding a more magical instruction. They came from everything around the model: how documents were ingested, how facts were represented, what tools the model could call, what policy guided those calls, and how answers were tied back to evidence.
That surrounding system is often described as the harness, and the term fits.
Think about Formula 1 for a second. The driver crosses the finish line, stands on the podium, and becomes the face of the win. But the race is not won by the driver alone. It is won by the car, the pit crew, the race engineers, the telemetry, the tire strategy, the simulations, the weather calls, and thousands of small decisions made before the lights go out.
Agents are similar. The model is the visible driver. The harness is the team, car, garage, and race strategy around it.
The agent is not just the model. The agent is the model plus its knowledge base, tools, runtime policy, retrieval strategy, safety rails, memory shape, and verification loop. Once you start seeing the system this way, a lot of agent engineering becomes less mysterious.
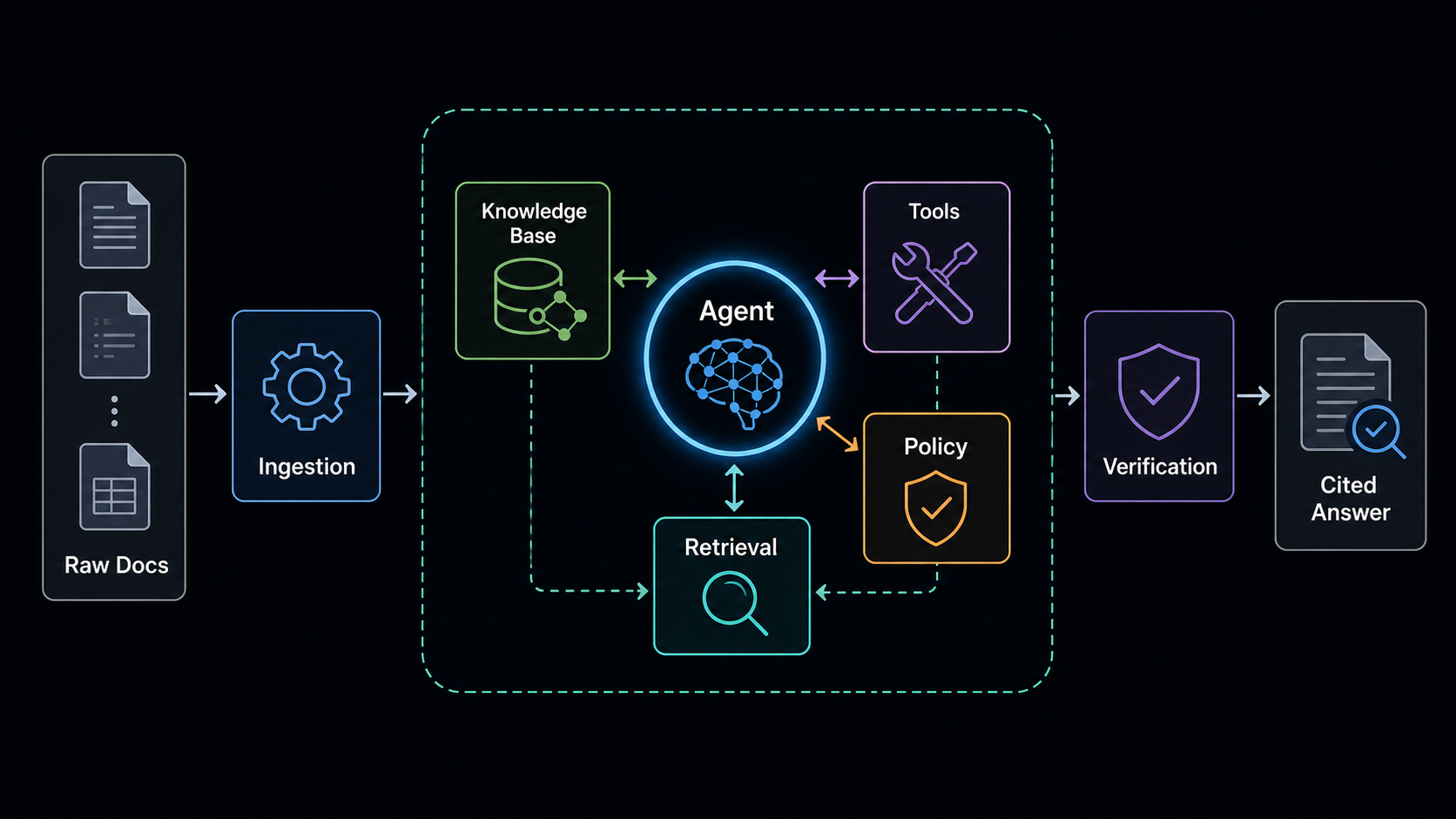
The Agent Is Not the System
It is tempting to describe an AI feature by naming the model behind it. In practice, that usually explains very little.
Two systems can call the same model and produce wildly different results. One feels vague, slow, and unreliable. The other feels precise, grounded, and useful. The difference is usually not the model alone. It is the operating environment built around it.
A serious agentic workflow needs more than a chat box:
This is where the engineering effort moves. Prompting is still part of the craft, but the larger discipline is harness engineering.
A Knowledge Base Is Built, Not Uploaded
One of the easiest mistakes to make is treating raw documents as the knowledge base.
Part of the inspiration for this came from Andrej Karpathy's recent llm-wiki idea file. The part that stuck with me was the shift away from asking an LLM to rediscover knowledge from raw chunks on every query, and toward having the LLM help maintain a persistent, structured knowledge layer over time.
Upload a pile of PDFs, split them into chunks, index them, and let the model figure it out. That can work for broad question answering, but it starts to struggle when the domain has structured facts, repeated entities, tables, yearly reports, ambiguous names, and source-sensitive answers.
In document-heavy workflows, the raw document is only the beginning. The useful knowledge base is the result of a properly designed ingestion pipeline.
That pipeline should produce multiple representations of the same source:
This changed how I think about retrieval. The knowledge base is not just a storage layer. It is a product of interpretation, normalization, and representation design.
Ingestion as Compilation
A useful mental model is to treat ingestion like compilation.
The raw document is source code. It contains the truth, but not always in a form the agent can use efficiently. The ingestion pipeline compiles that source into artifacts optimized for runtime use.
For example:
This matters because agents are context-limited. If every user question forces the model to reread large raw files, the system becomes slow, expensive, and inconsistent.
Good ingestion moves expensive interpretation earlier. At query time, the agent should mostly retrieve, compare, verify, and synthesize.
Retrieval Quality Depends on Representation Quality
A lot of retrieval discussions focus on the search algorithm: vector search, hybrid search, keyword search, reranking, and so on. Those choices matter, but they are only half the story.
The quality of retrieval also depends on the quality of the thing being retrieved.
If the index contains raw chunks with weak context, even a strong retrieval layer has to work harder. If the index contains intentional representations written in the language users are likely to ask with, even simple retrieval can perform surprisingly well.
For narrow domains, this can be a major advantage. You do not always need the heaviest retrieval stack. Sometimes you need better artifacts:
The lesson is not that one retrieval technique is always better. The lesson is that retrieval should be designed together with ingestion. Search over well-shaped artifacts is very different from search over arbitrary chunks.
Fewer Agents Can Be Better
Another lesson: more agents do not automatically make a system more intelligent.
It is easy to design a pipeline with a router agent, a search agent, a data agent, a synthesis agent, and perhaps a critic agent. This looks clean on a diagram. Each agent has a role. Each stage has a responsibility.
But in practice, this can introduce problems:
For many domain-specific systems, a single capable agent with the right tools can be more reliable.
One model can search, inspect structured data, read supporting evidence, fall back when a path fails, and write the answer in one continuous loop. The key is that the loop needs a good harness: clear tools, bounded context, retrieval policy, and stopping rules.
The point is not "never use multiple agents." The point is to avoid adding orchestration complexity before the problem actually needs it.
The ROLE File Is the SOUL of the Agent
The most underrated part of an agent system is the ROLE file or instruction document. Slightly dramatically, it is the SOUL of the agent: the place where its operating instincts are written down.
It is easy to think of this as just a long prompt. I think that undersells it. A good role file is closer to runtime policy.
It should define:
This is where domain behavior becomes explicit.
For example, a numeric question should usually go to structured metrics before narrative text. A comparison across many entities should use targeted field extraction rather than reading entire files repeatedly. A missing document should trigger an availability check before the agent tells the user that the data does not exist.
These are not just prompt preferences. They are operating rules. They make the model more consistent because they reduce the number of decisions it has to improvise.
Tools Should Encode Good Research Behavior
Tool design has a huge impact on agent quality.
A blunt tool like read_file gives the model access, but not much guidance. It invites the agent to consume too much context and then reason from a noisy blob.
Better tools encode useful research behavior:
This is a subtle but important shift. The tools are not just capabilities. They are affordances. They shape how the model thinks through the task.
A good harness gives the model tools that match the workflow of a careful human analyst: look up the exact field first, inspect surrounding context only when needed, broaden search if the specific path fails, and preserve the source trail.
Entity Resolution Belongs Before Reasoning
Many real-world domains have messy names.
Users type abbreviations, aliases, old names, short names, and ambiguous references. If the model has to resolve all of that while also answering the question, errors creep in early.
A better pattern is to normalize entities before the main reasoning loop whenever possible.
That means resolving user-facing names into canonical identifiers, detecting ambiguity, and passing the resolved context into the agent. The agent can then operate on stable IDs instead of guessing which entity the user meant.
This is one of those mechanisms that makes an agent feel smarter without asking the model to be smarter. You remove avoidable ambiguity from the environment.
Trust Requires Lineage
For serious workflows, an answer is not enough.
If the system returns a number, users should be able to know where that number came from. Which source document? Which extracted artifact? Which field? Which year? Was it normalized? Was it inferred?
This is especially important in research, reporting, compliance, finance, healthcare, education, and any workflow where people make decisions from the output.
The harness should preserve lineage as a first-class concern:
Without this, the agent may sound confident but remain operationally hard to trust.
Harness Complexity Should Match the Problem
The goal is not to build the most agentic system possible.
The goal is to solve the problem with the least machinery that preserves reliability, debuggability, and room to grow.
Sometimes that means a single model call. Sometimes it means a tool-use loop. Sometimes it means multiple agents. Sometimes it means no agent at all, just a deterministic workflow with an LLM at one step.
Harness engineering is partly about restraint. Before adding another agent, ask:
These questions tend to produce simpler systems.
Conclusion
The first wave of agent building was obsessed with prompts. The next wave is going to be about harnesses.
Not because prompts stopped mattering, but because useful agents need an operating environment. They need knowledge that has been prepared for use, tools that expose the right actions, policies that guide behavior, orchestration that matches the problem, and outputs that can be traced back to evidence.
The best agent systems I have worked through did not improve because they added more moving parts. They improved because the model was given a better world to operate in.
That is the shift from prompt engineering to harness engineering.